My research program centers on stable algorithms for forward and inverse scientific computing problems. Across everything I work on, three commitments stay constant: stability (algorithms that do not silently fail under noise, discretization, or optimization choices), interpretability (models scientists can reason about: sparse, symbolic, mechanism-level), and usability (methods released as well-tested open-source software). Here is an overview of what I have been working on at Northwestern.
Discovering equations from data: SODAs and DAE-FINDER
A central problem in scientific machine learning is inferring governing equations directly from measurements. Our algorithm SODAs (Sparse Optimization for Discovery of Differential-Algebraic Systems), published in Proceedings of the Royal Society A (2026), extends sparse equation learning to differential-algebraic systems. This matters because many real systems are naturally DAEs: chemical reaction networks with conservation laws, power grids with load constraints, and electrochemical interfaces. SODAs recovers both the dynamic equations and the algebraic constraints without first reducing the system to ODEs, which preserves the physical structure that reduction destroys.
 SODAs on the IEEE-39 bus power grid: algebraic constraints recovered reliably as perturbation data accumulates, even under 20–40dB measurement noise.
SODAs on the IEEE-39 bus power grid: algebraic constraints recovered reliably as perturbation data accumulates, even under 20–40dB measurement noise.
We have demonstrated SODAs on:
- Chemical reaction networks, preserving conservation laws and quasi-steady-state structure natively.
- Mechanical systems, recovering constraints and energy conservation of a nonlinear pendulum directly in Cartesian coordinates.
- Power-grid dynamics, scaling to the IEEE-39 bus benchmark under significant noise.
- Battery and electrochemical models, inferring material parameters such as diffusivity, ion mobility, and interfacial reaction rates.
The algorithms ship in DAE-FINDER (dae-finder on PyPI), a model-agnostic Python package I designed and released. Any algorithm exposing a scikit-learn style .fit()/.score() interface plugs in, so SINDy, Weak-SINDy, IDENT, and DAE-FINDER variants can be benchmarked on a common footing. That architecture is a direct descendant of the asset-agnostic pricing-library framework I worked on at Citigroup.
Why these methods fail, and how to fix them
Dictionary-based model discovery is often ill-posed in ways that have been largely overlooked: correlated features, conservation laws, and limited excitation make the underlying linear algebra ill-conditioned, and regularization alone does not fix it. With collaborators at Northwestern, I have been connecting these failure modes to classical inverse-problem theory and developing fixes, including a QR-based approach that simultaneously orthogonalizes the candidate library and determines a minimal basis. A companion case study on systems biology models is under review at SIAM Journal on Life Sciences (arXiv:2603.11330), and two senior-author manuscripts on stabilization and on a multiple-shooting framework for parameter inference are in preparation.
 SVD diagnostics of a chemical-reaction-network candidate library at 15% noise: structural redundancy in the library shows up as a collapsing singular-value spectrum, exactly where naive sparse regression becomes fragile.
SVD diagnostics of a chemical-reaction-network candidate library at 15% noise: structural redundancy in the library shows up as a collapsing singular-value spectrum, exactly where naive sparse regression becomes fragile.
We are also extending neural ODEs with monomial and polynomial augmentation, which improves extrapolation beyond the training region and allows symbolic structure to be recovered from the trained model.
Fast solvers for electrochemical systems
At the Trienens Institute for Sustainability and Energy, I lead the development of fast, flexible Galerkin weak-form solvers for coupled Poisson-Nernst-Planck systems with nonlinear Butler-Volmer boundary conditions, modeling charged-species transport in electrochemical reactors with complex geometries and heterogeneous media. The solvers are designed from the start for inverse-problem compatibility: differentiable, suitable for parameter estimation, and usable inside model-discovery pipelines. Applications include electrochemical reactor design, battery materials, and carbon recycling, in collaboration with chemical engineers at Northwestern.
Agentic AI for scientific computing
The newest thread in my work develops protocols, validation strategies, and reusable agentic skill sets for using frontier AI agents (Claude Code, Codex/GPT, Gemini) in scientific computing: numerical solvers for ODEs and PDEs, parameter estimation for stiff nonlinear systems, and HPC orchestration. The anchor application is the coupled PNP inverse problem above, where carefully steered agentic AI has measurably accelerated both the theoretical and computational sides of the project.
The central question is one of trust: how does a computational scientist structure instructions so that an AI agent stays within necessary and sufficient bounds, minimizes hallucination, and produces verifiable scientific work? In parallel, I care about accessibility: codified workflows and well-engineered context can let researchers on smaller, less expensive models accomplish much of what is currently associated with frontier models, which directly lowers the cost barrier for institutions with limited research-computing budgets.
 The trust loop: agentic skill sets carry discipline-specific context to the agent; validation protocols audit every output before results are trusted.
The trust loop: agentic skill sets carry discipline-specific context to the agent; validation protocols audit every output before results are trusted.
I am teaching a new project-based graduate course, Agentic AI for Scientific Computing, at Northwestern Applied Mathematics in Fall 2026, with funded frontier-model access for enrolled students. Course outputs feed back into the research program’s library of reusable skill sets.
Earlier work: multiphysics PDEs and domain decomposition
My PhD work at the University of Pittsburgh produced domain-decomposition and time-splitting methods for the Biot system of poroelasticity and a space-time multiscale mortar mixed finite-element method for parabolic equations, with first-author papers in SIAM Journal on Numerical Analysis, Computer Methods in Applied Mechanics and Engineering, and Computational Geosciences. The MPI-based parallel solvers from that era are open source, and the forward-solver expertise remains the foundation for everything above: reliable inverse problems and trustworthy model discovery need reliable forward solvers.
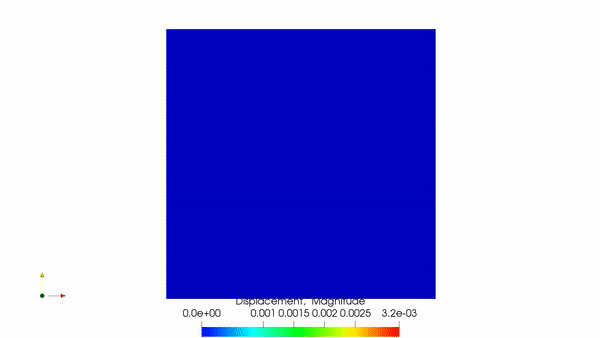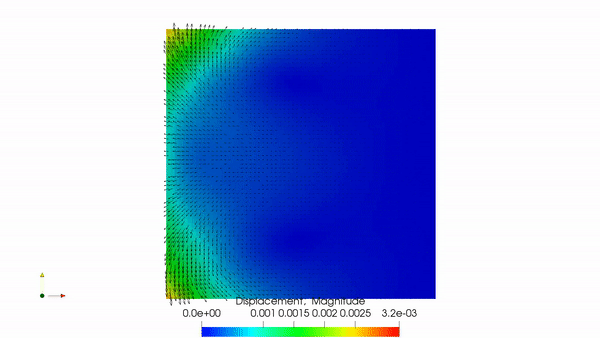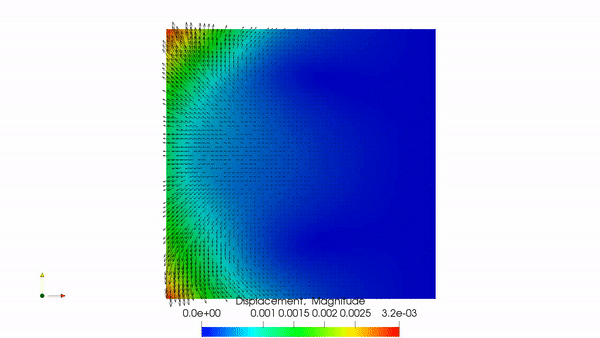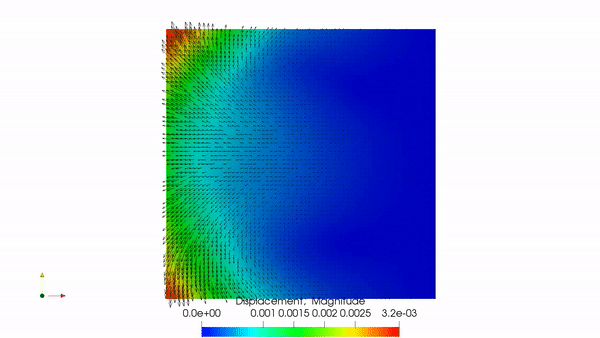 Poroelastic flow simulated with BiotDD, my MPI-parallel domain-decomposition solver for the Biot system.
Poroelastic flow simulated with BiotDD, my MPI-parallel domain-decomposition solver for the Biot system.
A full list of papers is on the Publications page, and the software is described on the Software page.